Case Study: Improving Object Detection Performance by Leveraging Synthetic Data
December 13, 2021
.jpeg)
Applied Intuition’s perception team has conducted a case study that uses synthetic data to improve a perception algorithm’s object detection performance on underrepresented classes in a real-world dataset.
Real-world data is indispensable when training object detection models for autonomous vehicle (AV) perception systems. Unfortunately, the real world doesn’t always easily provide all the data needed for successful training. For example, classes such as cyclists and motorcyclists may occur less frequently than pedestrians and cars, making it difficult for perception models trained on real-world data to correctly detect them (Figure 1). Similarly, the most dangerous situations such as accidents may be hidden in the last few percent of test drives.

Even though underrepresented classes and long-tail events occur less frequently in the real world, object detection models still need to be trained to handle them just as well as more common classes and situations. In the past few years, perception teams have started to utilize synthetic data to help address some of these limitations in real-world datasets. There still exists a domain gap between real-world and synthetic data, which is important to acknowledge, but recent methods are overcoming this gap with a combination of improved synthetic data and new machine learning training strategies.
To demonstrate this use case, Applied Intuition’s perception team has conducted a case study that uses synthetic data as a supplemental training resource to address a class imbalance found in a real-world dataset. The study shows that synthetic data may be used to help mitigate class imbalances and address areas where real-world data is limited.
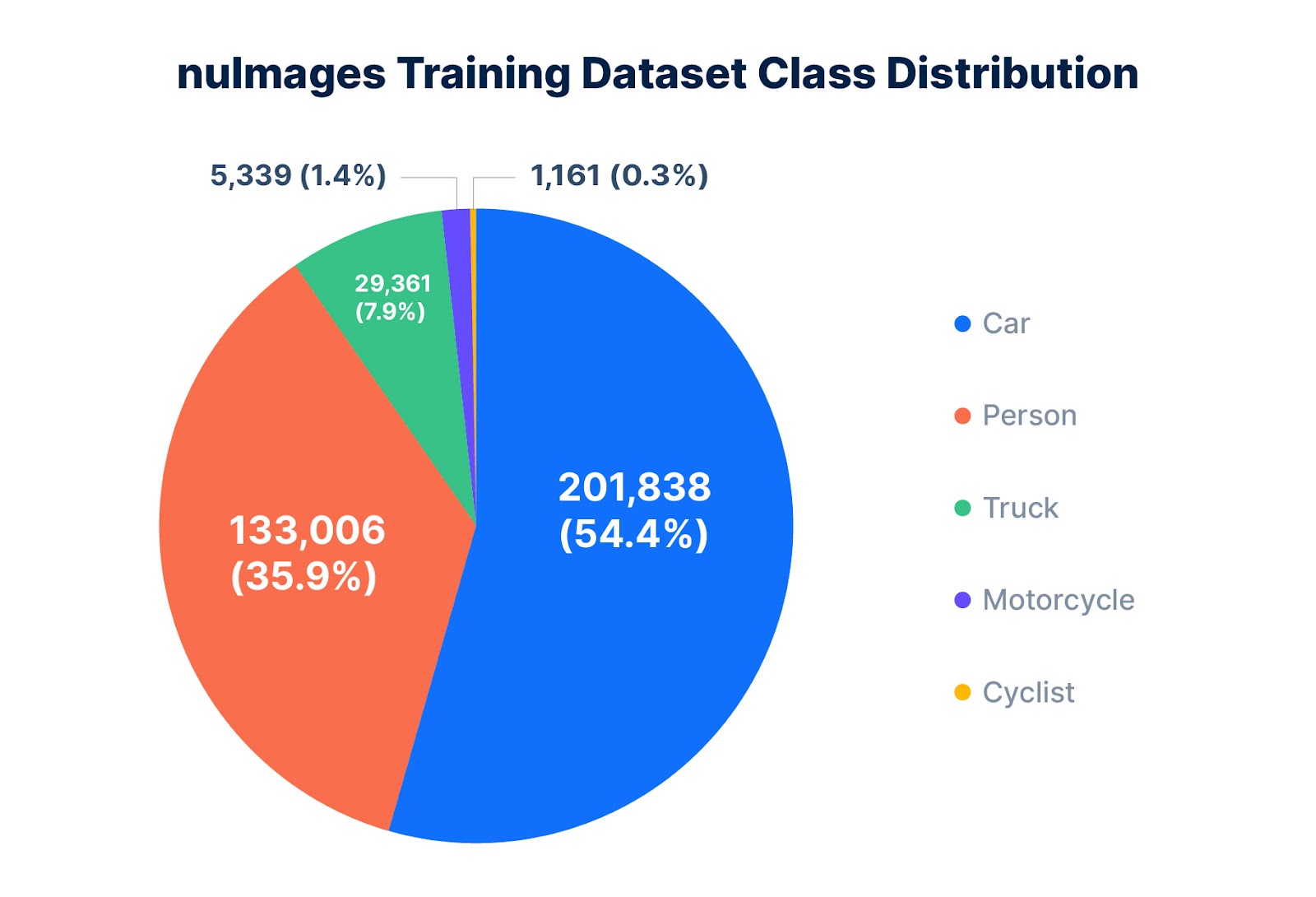
This case study uses nuImages—a commonly used dataset by nuScenes—as a baseline training dataset. In the dataset, the cyclist class occurs 170 times less frequently than more prominent classes such as cars and pedestrians (Figure 2).
The study generates and uses a synthetic dataset to improve a perception algorithm’s object detection performance on cyclists while retaining or improving object detection performance on other classes. It also explores whether the use of synthetic data can reduce the amount of real-world data needed to improve a model’s object detection performance.
The study consists of the following steps:
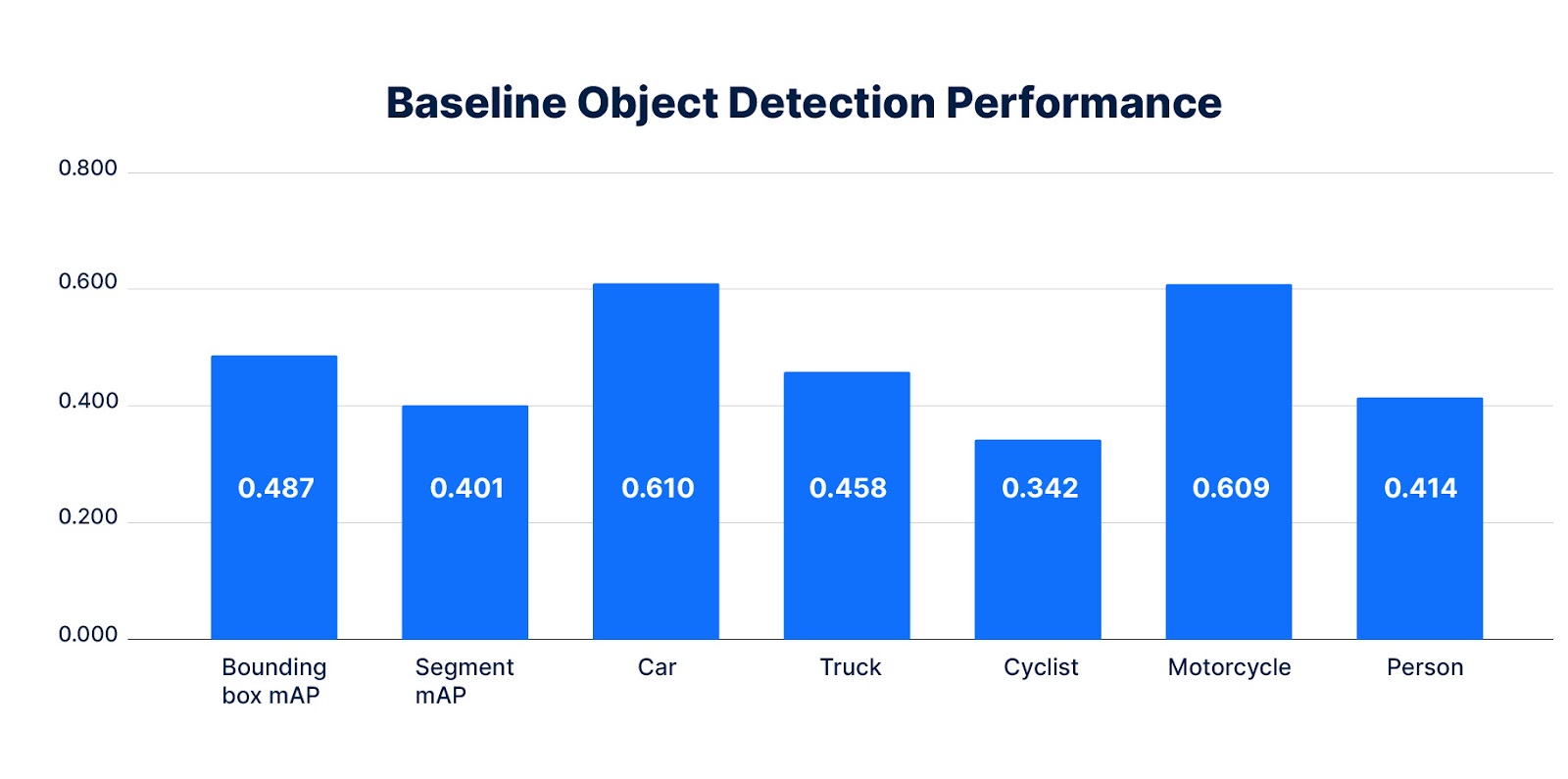
First, it is measured how a perception model reacts to a class imbalance in the real-world nuImages data. A Cascade Mask R-CNN perception model is trained on this dataset until convergence. Its resulting object detection performance is lower on the cyclist class compared to all other classes (Figure 3).
Next, synthetic data is generated to upsample the underrepresented cyclist class (Figure 4). This case study uses procedural 3D environment generation, automatic scenario creation, and a synthetic data generation pipeline to enable this process.
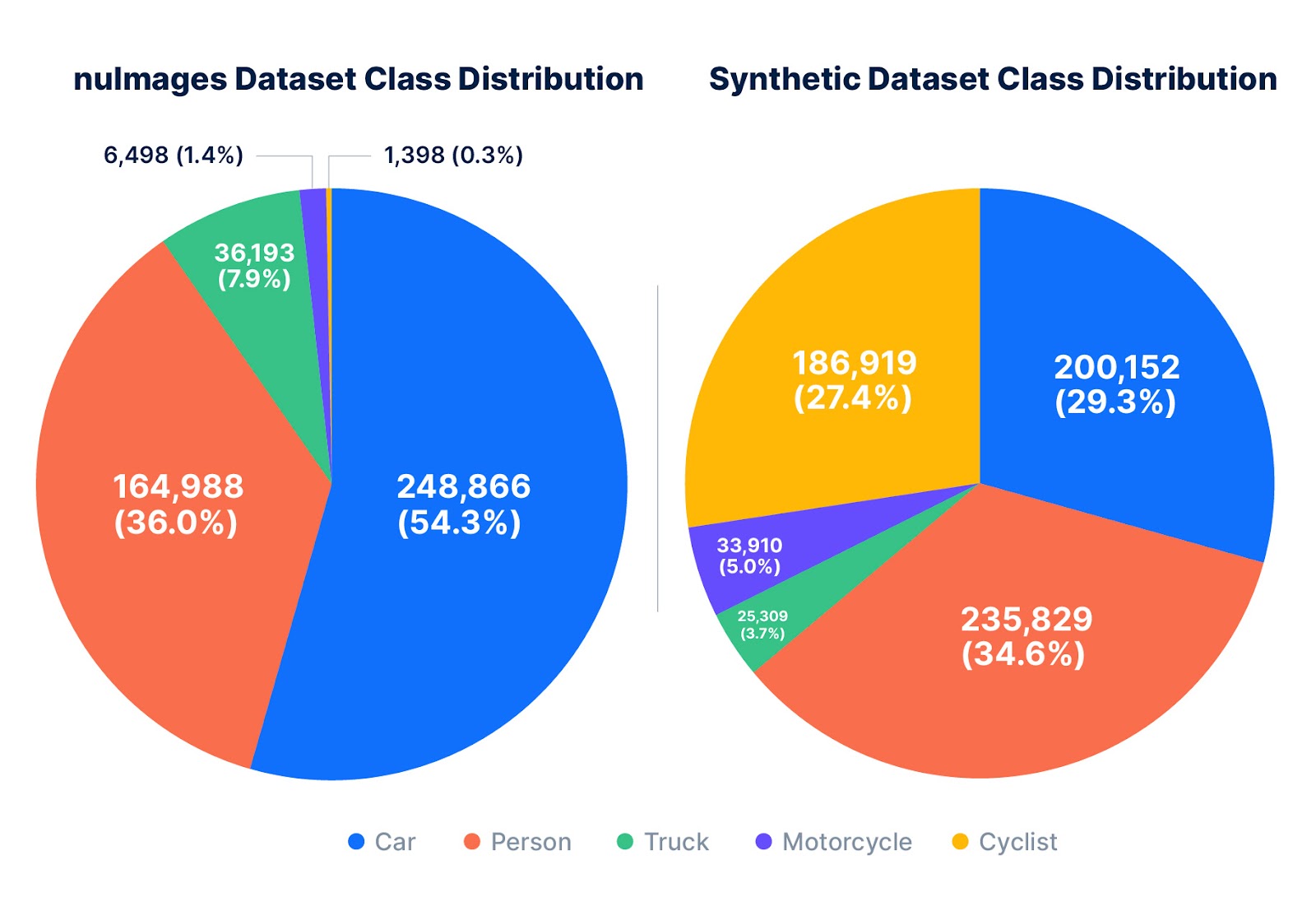
The above synthetic dataset is then used to improve model performance in the following experiments.
Synthetic data and real-world data are combined into one large training dataset. Batches that contain both real-world and synthetic data are randomly sampled from this dataset during training. Two trials are conducted to adjust the ratio of synthetic to real-world data and explore whether using more synthetic data and less real-world data impacts the model’s object detection performance:
A model is trained to convergence on only the synthetic dataset using a small holdout synthetic set for validation. Three trials are then conducted to fine-tune the model on the following amounts of real-world data:
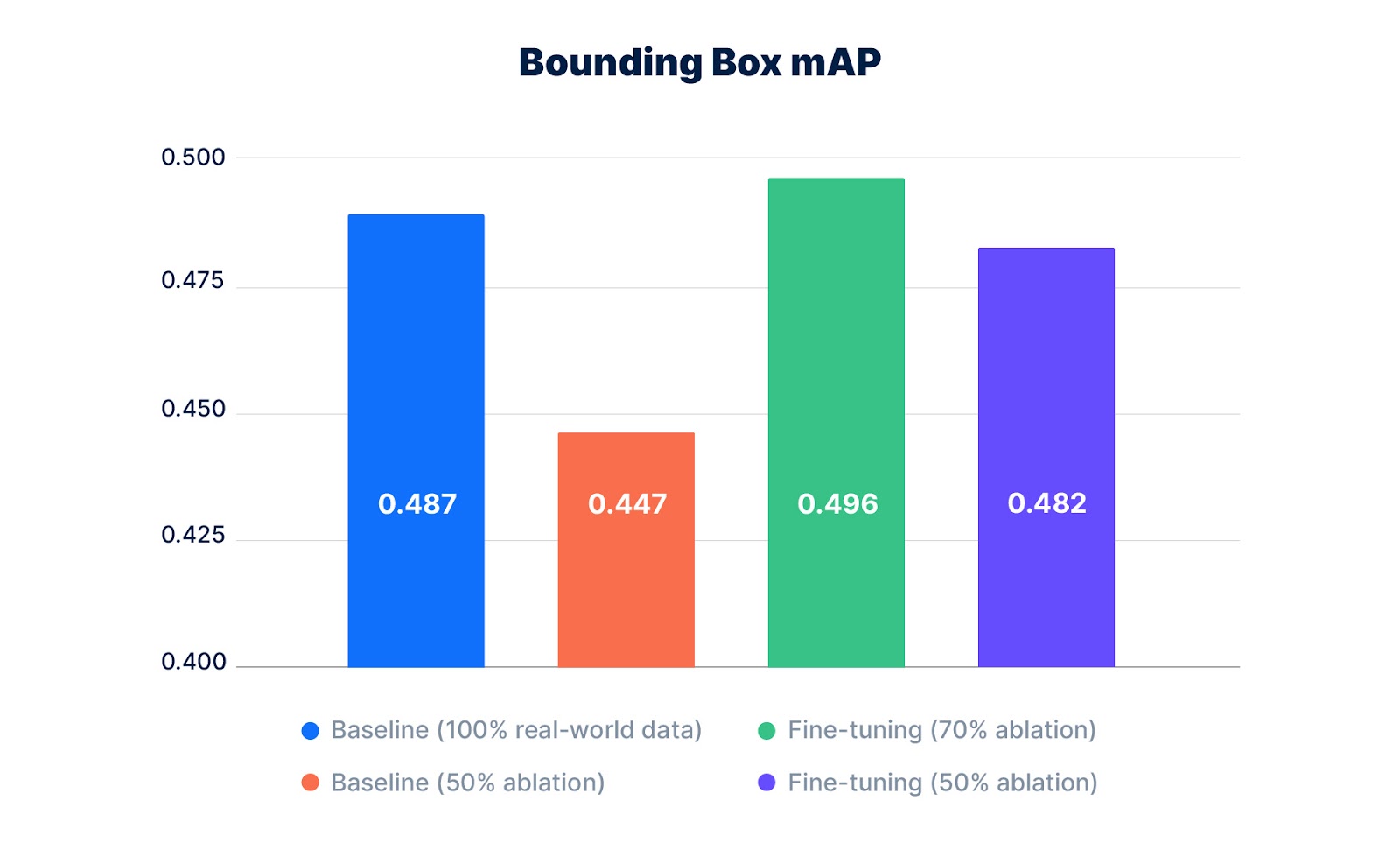
Compared to the baseline model with 100% of the real-world data, mixing synthetic and real-world data (mixed training) leads to improvements on the cyclist class (Figure 5). Pre-training a model on synthetic data and then fine-tuning it on 100% of the real-world data (fine-tuning without data ablation) shows the highest performance improvement, outperforming the baseline model consistently on all classes (Figure 5).
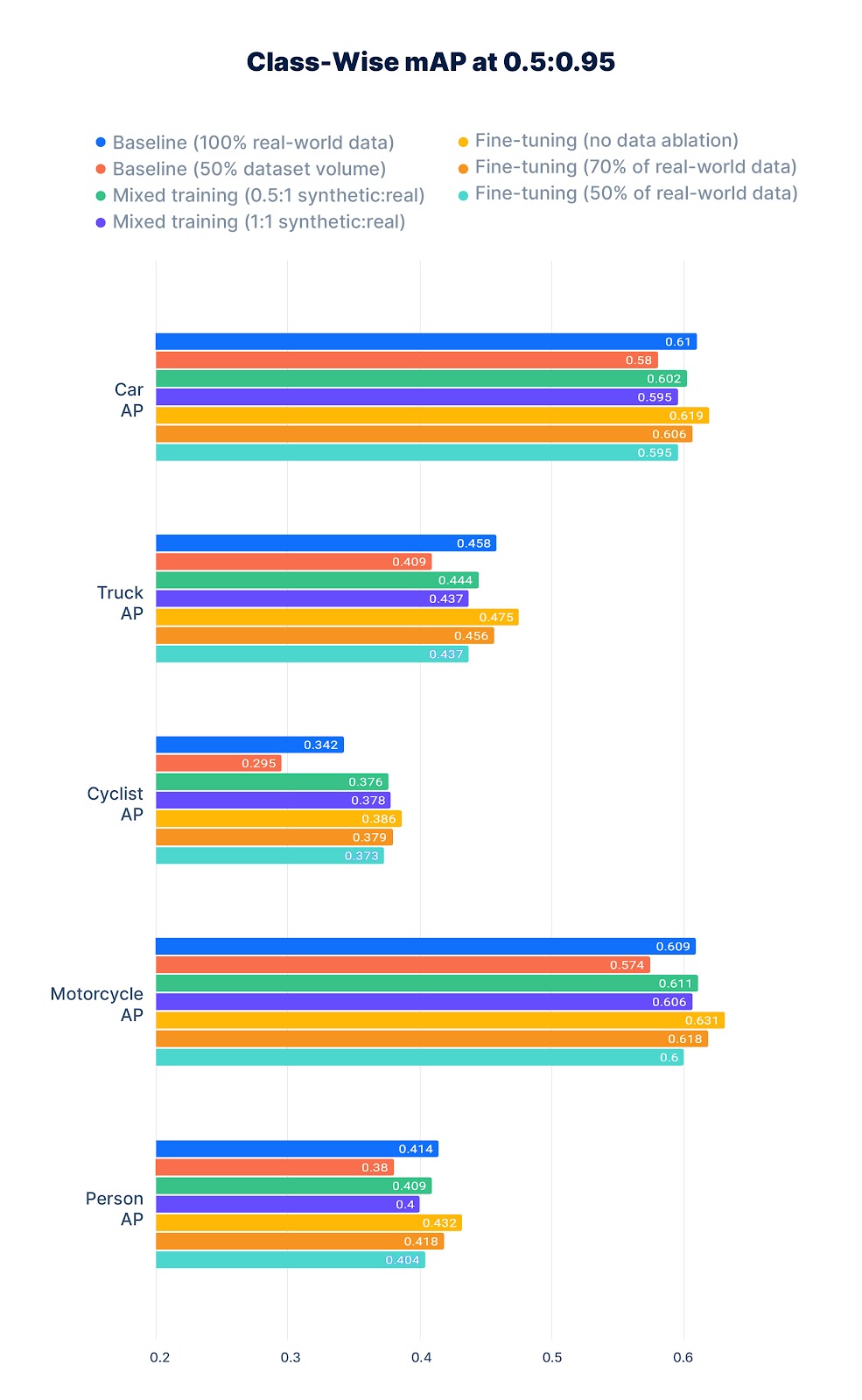
Pre-training a model on synthetic data and then fine-tuning it on 70% of the real-world data (fine-tuning with data ablation) leads to an improved performance, both on the cyclist class (Figure 5) and overall (Figure 6).
The case study suggests that synthetic data can help improve object detection performance in difficult cases. The following images show cases in which the baseline model fails to adequately detect a cyclist while the model pre-trained on synthetic data succeeds (Figures 7 a) - 7 c)).



This case study shows an early indication that synthetic data is a useful supplementary tool to real-world datasets when training AV perception models on both nominal and edge cases. Even though situations such as fallen objects, pedestrians or live animals on a highway, and bad visibility due to dense fog are rare, AVs must be prepared to safely navigate them. Synthetic data can help address class imbalances by improving a perception model’s object detection performance on minority classes such as cyclists. Synthetic data also provides a fast, cost-effective, and ethical way to generate training datasets and target rare or difficult cases when real-world data is too infrequent or dangerous to collect.
Contact our team of perception engineers to learn more about Applied Intuition’s synthetic datasets.
.webp)
.webp)
