.webp)
.webp)

Applied Intuition’s log management handbook explains the journey of a drive data file from inception to storage. Our three-part blog post series highlights different parts of the handbook. Read part 1 for an introduction to the log management life cycle. Part 2 lays out drive data exploration best practices with a particular emphasis on surfacing interesting events. This third and last part of our blog post series focuses on one of the workflows that drive data enables: Log-based test case creation. Keep reading to learn more about this topic, or download our full handbook below.
Log-Based Workflows
Within any autonomy program, a variety of different teams leverage drive data for their work. Each team has unique workflows with specific tooling requirements. Triage teams need to investigate each issue from field testing as quickly as possible. Perception engineers need to curate datasets for machine learning (ML) model development and evaluate object tracking performance. Motion planning teams need to create test cases based on recorded drive data to evaluate planned behavior. A good log management platform should support all of these workflows.
Our log management handbook discusses how triage, perception, prediction, and motion planning teams can leverage log-based workflows to make the most of their collected drive data. The handbook discusses the following workflows in detail:
- Triaging issues from the field (Figure 1)
- Curating datasets to train ML models
- Using ground-truth labels to analyze perception performance
- Improving prediction performance
- Improving motion planning performance
- Creating test cases from a drive data file
- Validating a supplier module using drive data

Creating Test Cases From a Drive Data File
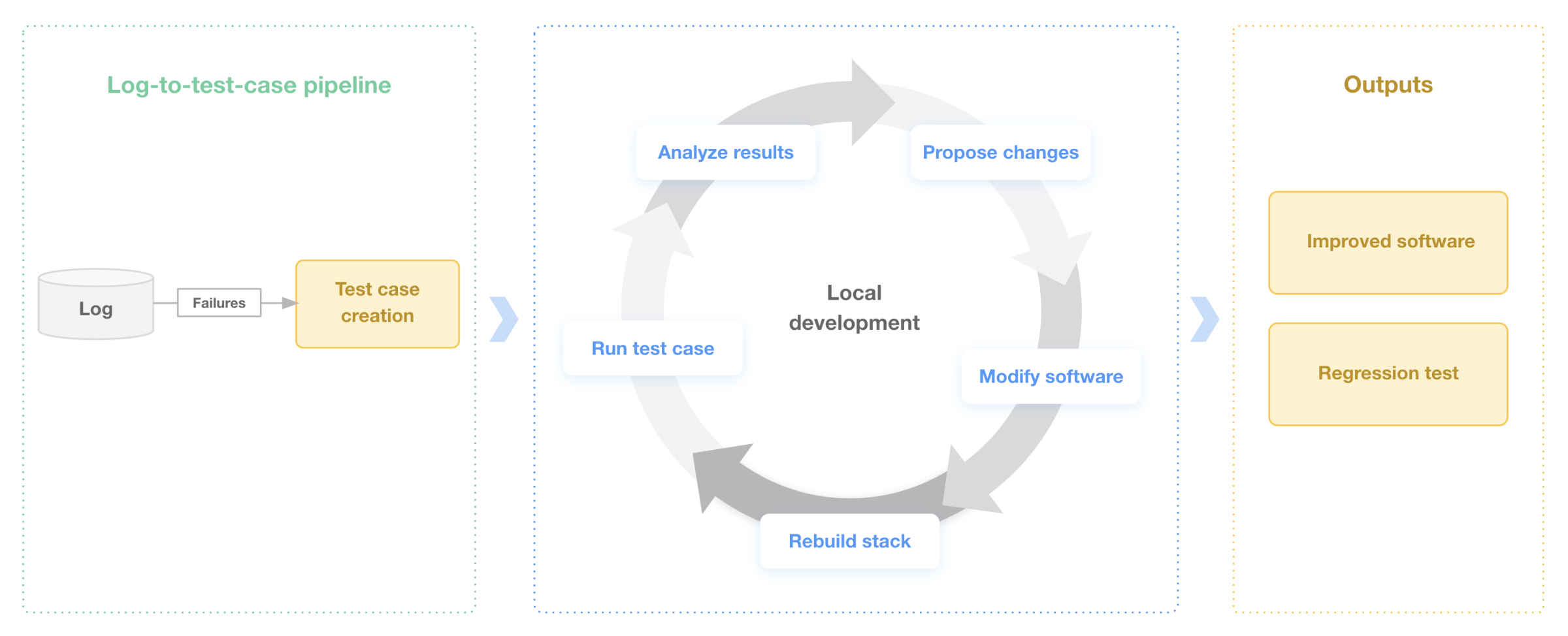
Having a log-based test case creation workflow helps autonomy programs improve perception, localization, and motion planning modules. Creating test cases from real-world drive data is one of the most effective ways to solve long-tail issues found during real-world testing. The workflow involves the following steps:
- Create a test case to reproduce the issue.
- Step through the test case to debug and root-cause the issue.
- Make a code change to resolve the issue.
- Confirm resolution of the issue by using the test case.
- Add the test case to a regression suite to ensure the issue does not reappear.
Reproducing an issue: Test case creation
Creating a test case from a drive data file should be quick—ideally one or two clicks. Alongside the test case, autonomy programs should also generate pass/fail rules that determine the test’s outcome. Once they have created a test case, teams should run it on their most recent autonomy stack to reproduce the issue.
There are two ways to create test cases from a drive data file: Scenario extraction and log re-simulation. Scenario extraction creates a synthetic test with actor behaviors sampled from the perception outputs in the drive data file. Log re-simulation replays the original recorded drive data to the autonomy stack without any synthetic signals. Both these types of test case creation have strengths and weaknesses. With scenario extraction, the extracted actor behaviors are typically robust to stack changes and portable between vehicle programs (e.g., an SAE Level 2 (L2) and an L4 autonomy program within the same organization). Log re-simulation has higher fidelity and is able to losslessly recreate the exact timing and content of signals sent to the autonomy stack.
Our log management handbook discusses both scenario extraction and log re-simulation in further detail and reveals how autonomy programs should choose between the two methods. This blog post focuses on log re-simulation only.
Log re-simulation
The conceptually simplest way to reproduce an issue from a drive data file is to run the autonomy stack against the previously recorded drive data. This method is called log replay. Log replay and log re-simulation both run the original messages or sensor data from the drive data file against the current autonomy stack. However, log re-simulation adds a simulator into the loop. This simulator controls signal timing and vehicle dynamics. The addition of the simulator achieves lossless fidelity and determinism (i.e., the guarantee that, given the same inputs, a simulation will always produce the same result, no matter how often or on which hardware teams run the simulation). This provides autonomy programs a greater chance to successfully resolve the long-tail issue. Because log re-simulation provides a higher degree of determinism than log replay, it is well suited for test case creation, especially compared to log replay alone.
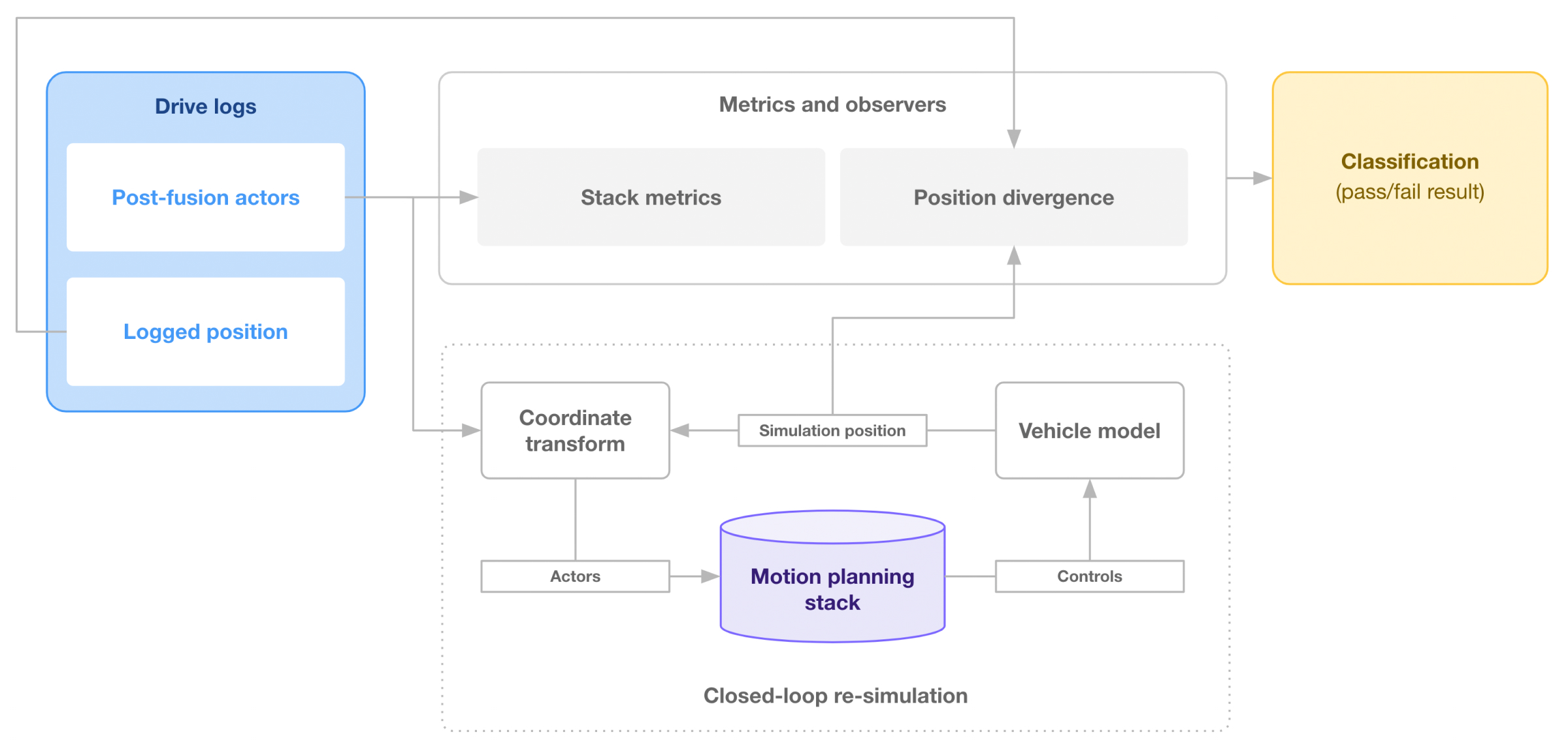
Autonomy programs can execute log re-simulation in two specific modes: Closed-loop re-simulation and open-loop re-simulation. Closed-loop re-simulation is most useful for disengagement analysis and motion planning development (Figure 2). It helps answer the question “What would have happened if the system continued without intervention”? Closed loop re-simulation involves a vehicle dynamics model interacting with the controller, and it can become inaccurate if the behavior of the re-simulated autonomous system diverges too much from the behavior in the original drive data file. Teams should be careful to keep a re-simulation test accurate when the loop is closed.
Open-loop re-simulation does not involve a vehicle dynamics model, so the position of the autonomous system in the re-simulation is fixed to the position in the original drive data file. Instead of testing the motion planning module, open-loop re-simulation helps test perception and localization modules (Figure 3). For example, testing the perception system in open-loop re-simulation involves playing sensor data from a drive data file into the perception software, and then grading the output via a scoring mechanism.
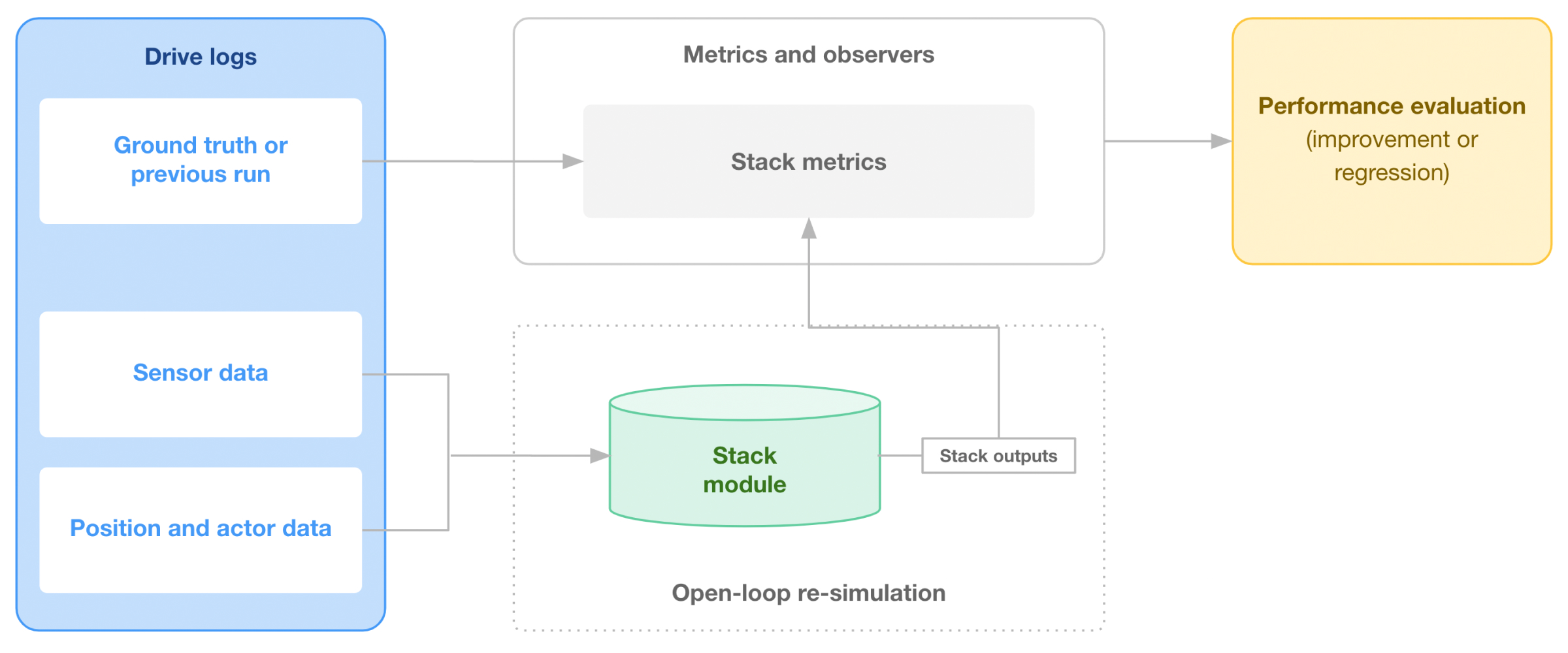
Systems engineers, triage teams, and motion planning engineers typically rely on closed-loop re-simulations, as they must assess the safety of the vehicle’s motion. Perception, prediction, and localization teams typically rely on open-loop re-simulation, as those module outputs can be graded without observing a change in vehicle position. For example, a localization system can be graded based on observing the outputs of the localization module, without involving a downstream system such as the planning module. Teams should choose the type of re-simulation that is right for them depending on the type of test case they want to create from a drive data file.
Read our full log management handbook to learn more about the strengths and weaknesses of log re-simulation and when autonomy programs should opt for scenario extraction instead.
Resolving the issue
Once autonomy programs have reproduced an issue by creating a test case and receiving a failing result, they can now resolve the issue locally by using real data from the drive data file to improve their autonomy stack. The log-based test case creation workflow makes this possible (Figure 4). The team should iteratively modify the autonomy stack and re-run the created test case. This iteration loop should be as quick as possible. Once the test passes, the stack changes are considered a true fix. It is important to note that a passing result for the created test case does not reduce the need for other software testing such as integration and unit tests.
Ensuring the issue does not re-appear
Successful autonomy programs ensure that their autonomous system does not fail twice in the same way. After reproducing and resolving a long-tail issue locally, teams should add the created test case to a regression test suite that regularly executes comprehensive tests in continuous integration (CI). If a long-tail issue appears unsolvable due to sensor or computing deficiencies, programs can add it to a progression test suite that evaluates the stack’s progress toward aspirational goals. Programs should also create dashboards that monitor the overall health of their autonomy stack and give all team members a high-level overview of stack performance over time.
In addition to these steps of the log-based test case creation workflow, our handbook also lays out how autonomy programs can utilize advanced re-simulation techniques such as fuzzing to stress-test their system even further. For example, fuzzing a test case allows teams to make a cut-in scenario more aggressive by changing the distance between the autonomous system and the vehicle that is cutting in front of it. Teams can create multiple test cases with different distances to find out where failures occur.
Conclusion
Different teams within an autonomy program can leverage different log-based workflows to power their autonomous systems development. The log-based test case creation workflow allows perception, localization, and motion planning teams to reproduce a real-world issue using scenario creation or log re-simulation, debug the issue, resolve it, and ensure it does not reappear. Learn more about log-based workflows and other parts of the log management process in our log management handbook.
Contact the Applied Intuition team with your questions about this handbook and read about Applied Intuition’s log management solutions on our website.
